들어가면서.. 😁
이번에 wanted에서 진행하는 2023년 2월 백엔드 프리온보딩 챌린지 과정에서 "MySQL 잘 사용하기"라는 주제를 공부하게 되었습니다!
사실 작년 4학년 2학기때 데이터베이스 설계 및 시각화 과목에서 다루었던 내용들이긴 하지만, 복습을 하는 목적으로 이번 챌린지에 신청하게 되었는데
이번에 챌린지를 수강하면서, 트랜잭션 개념과 동시성 제어와 관련된 부분들의 개념을 CS 지식을 정리하는 차원에서 정리해보려고 합니다.
그럼 이제 제가 공부한 흐름에 맞춰서 한번 정리해 보도록 하겠습니다.
Transaction(트랜잭션)
우선 트랜잭션부터 살펴봅시다.
데이터베이스에서의 Transaction이란 atomic 하게 처리할 수 있는(쪼갤 수 없는 최소 단위를 처리한다는 뜻) 논리적인 작업의 단위를 의미합니다.
데이터베이스에서 트랜잭션은 하나 이상의 데이터베이스 연산(database operations)의 집합 형태로 구성되는데, 데이터베이스 연산은 데이터 삽입, 수정, 삭제 또는 table이나 index 같은 데이터베이스 객체의 추가, 수정, 삭제등의 작업 등을 의미합니다.
트랜잭션에 대한 연산으로 두 가지가 있는데 바로 commit과 rollback입니다.
- commit: 트랜잭션으로 인한 변경 사항을 데이터베이스에 반영
- rollback: 트랜잭션으로 인한 변경 사항을 취소
트랜잭션이 데이터베이스에서 안전하게 수행되기 위해서는 ACID라는 요건들을 갖추어야 합니다.
ACID 한 Transaction 설계란??
ACID는 우선 4가지 단어의 앞글자를 따서 만들어진 말로 각각 Atomicity, Consistency, Isolation, Durablility를 의미합니다.
우리말로 바꿔보면, "원자적이고 유지되며 고립돼 있고, 마지막으로 지속가능하도록 트랜잭션을 설계해야 한다"고 이해할 수 있습니다.
ACID라는 속성들은 데이터베이스가 무결성(integrity)을 유지하기 위해 굉장히 중요한 요소이며, 각각의 성질을 다음과 같이 더 자세하게 정리해 봤습니다.
- Atomicity(원자성): 트랜잭션 내의 모든 작업들이 모두 성공하거나, 모두 실패해야 한다.
- Consistency(일관성): 각각의 트랜잭션이 실행된 이후에도 데이터베이스는 유효한 상태로 유지되어야 한다. (제약조건들을 준수한 무결한 상태로 남아야 한다)
- Isolation(격리성): 다수의 트랜잭션이 동시에 수행된다고 하더라도, 트랜잭션 간 간섭이 없어야 한다.
- Durability(내구성): 일단 트랜잭션이 성공적으로 커밋된 경우 데이터베이스에 반영된 변경 사항은 어떠한 오류에도 영구적으로 유지되어야 한다.
이렇듯 데이터베이스 관리 시점에서 트랜잭션이라는 개념은 데이터베이스의 무결성을 유지하기 위한 점에서 핵심적인 개념이라고 볼 수 있습니다.
여기서 데이터베이스의 무결성 부분은 또 하나의 글로 정리해도 부족함이 없는 내용이기 때문에, 다음에 정리해 보도록 하겠습니다.
동시성 제어
앞선 트랜잭션 개념 부분에서도 보았듯, ACID 특성 중 격리성(Isolation) 성질을 준수하기 위해서는 동시에 동작하는 다수의 트랜잭션이 서로 간섭하지 않고 동작하도록 보장할 수 있어야 합니다.
여러 트랜잭션이 동시에 동작하면서 각자 다른 데이터에 접근해서 다룰 수 있다면 좋겠지만, 당연하게도 여러 트랜잭션이 같은 데이터에 접근하는 경우에 대한 추가 처리가 필요합니다.
데이터베이스에서 격리 수준에 따라서 다음과 같은 문제들이 발생 가능합니다.
- lost update: 두 개의 트랜잭션이 같은 시점에 같은 데이터를 수정할 때, 한 트랜잭션에 의한 변경 사항을 잃게 되는 경우 (다른 트랜잭션이 이후에 추가적으로 변경하기 때문)
- dirty read: 한 트랜잭션이 다른 트랜잭션에 의해 이미 수정된 데이터를 조회한 경우 → 부정확한 결과를 유발하는 일관되지 않은 상태의 데이터를 조회하게 된다.
- non-repeatable read: 반복할 수 없는 조회, 한 트랜잭션 내에서 같은 데이터를 여러 번 조회하는 경우 중간에 수정이 되어 일관되지 않은 조회 결과를 유발할 수 있다.
- phantom read: 한 트랜잭션에서 특정 조건에 맞는 데이터를 조회하는데, 중간에 다른 트랜잭션에 의해 데이터가 수정되는 경우 조회 도중에 그 조건에 맞는 조회 결과가 바뀔 수 있다.
따라서 이런 문제점을 해결하기 위해서 동시성 제어가 필요해지며, 동시성 제어의 목표는 다수의 트랜잭션이 동시에 처리되는 순간에서도 database가 일관된 상태를 유지하도록 하는 것이라고 할 수 있습니다.
동시성 제어를 해결하는 방법으로는 크게 두 가지 방식이 있습니다.
- Locking method: 각 트랜잭션이 접근하는 data에 lock을 부여해서 lock을 보유하고 있는 동안에만 특정 데이터에 접근할 수 있는 권한을 부여한다. Lock의 종류에 따라 데이터에 대한 권한이 다르며, lock을 보유해야 권한에 맞는 작업을 수행할 수 있다.
- Timestamp based method: 각 트랜잭션에게 unique 한 timestamp를 부여해 그 timestamp 내에서만 실행할 수 있도록 제어권을 넘겨준다. 만약 트랜잭션 실행 도중 더 높은 timestamp를 갖는 다른 트랜잭션에 의해 수정되고 있는 데이터를 조회하는 경우 현재 진행 중인 트랜잭션은 대기하게 된다.
Lock level
이 중에서 Locking 방식을 조금 더 공부해 봅시다.
Lock은 다수의 트랜잭션이 같은 데이터를 동시에 접근하는 상황에서 동시성 제어를 하기 위한 두 가지 주요 방법 중 하나로 다음과 같이 lock의 종류를 나열할 수 있습니다.
- Shared Lock: 다른 트랜잭션이 데이터를 조회하는 것은 허용하지만, 데이터 작성 및 수정은 금지하는 lock.
- Exclusive Lock: 다른 트랜잭션이 데이터에 접근하는 것을 막는 lock. 데이터 조회와 작성 및 수정 모두 불가능하다.
Lock Compatibility
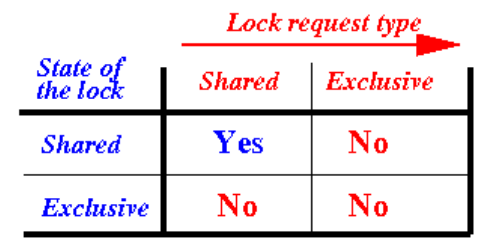
위의 표에서 state of lock은 현재 자원에 부여된 lock의 종류를 의미하고, lock request type은 해당 자원에 요청되는 lock의 유형을 의미합니다.
표를 보면 알 수 있듯이, shared lock이 부여된 자원에는 shared lock만 요청할 수 있고, exclusive lock이 부여된 자원에는 어떠한 lock도 요청할 수 없음을 확인할 수 있습니다.
요약하자면, 다른 트랜잭션에서의 조회만 허용한 상태에서는 shared lock을 허용해 조회가 가능하도록 할 수 있지만, 조회를 포함한 접근 자체를 차단하는 exclusive lock이 부여된 자원에 대해서는 어떠한 접근도 차단하는 것으로 이해할 수 있었습니다.
또한 lock을 적용할 수 있는 다양한 자원(resource)의 범위가 있는데, 이를 granularity level이라고 합니다.
Granularity level
- rows (datas)
- page
- table
- database
Transaction isolation level (트랜잭션 격리 수준)
앞서도 언급했던, 트랜잭션 격리 수준은 데이터베이스 상에서 동시에 여러 트랜잭션이 실행될 때, 다른 트랜잭션에게 보이는 데이터의 격리 정도를 의미합니다.
격리 수준에 따라서 해당 트랜잭션이 변경하고 있는 데이터가 다른 트랜잭션에게 어떻게 조회되는지를 정할 수 있게 됩니다.
격리 수준은 다음과 같이 4단계가 있습니다.
- Read Uncommitted
- 커밋되지 않은, 즉 다른 트랜잭션이 수정 중인 data를 조회할 수 있습니다. 제일 낮은 수준의 transaction isolation level이라고 할 수 있습니다.
- dirty reads(DB에 반영되지 않은 수정 사항 조회됨), non-repeatable read(중간에 커밋된다면?), phantom read(중간에 커밋된다면?) 같은 문제점을 해결할 수 없습니다.
- Read Committed
- 커밋된 데이터만을 조회합니다. 따라서 다른 트랜잭션에서 수정중인 데이터는 조회할 수 없고, 오직 DB에 반영된 데이터에 한에서만 조회할 수 있습니다.
- dirty read 문제는 해결할 수 있지만, non-repeatable read(중간에 커밋된다면?), phantom read(중간에 커밋된다면?)는 해결할 수 없습니다.
- Repeatable Read
- 하나의 트랜잭션을 실행하는 도중에는 같은 데이터에 대해 같은 결과의 조회를 보장하는 격리 수준입니다.
- 첫 번째 조회 당시 존재했던 모든 데이터는 이후의 조회 상황에서도 유지됩니다. (다른 트랜잭션에 의해 삭제당했을지라도 조회 가능합니다.)
- non-repeatable read 문제를 해결할 수 있습니다. phantom read는 X (새로운 데이터가 추가로 조회되는 상황은 여전히 발생)
- Serializable
- 각 트랜잭션이 완전히 격리된 상태로 실행됩니다. 동시에 실행되는 트랜잭션이 없는 상황
- phantom read 문제까지 해결할 수 있습니다.
- 다만, 효율이 떨어질 수 있습니다.
트랜잭션의 격리 수준에 따라 발생하는 문제 종류는 다음과 같은 표로 정리할 수 있습니다.
| Serializable | Repeatable Read | Read Committed | Read Uncommitted | |
| phantom read | x | o | o | o |
| non-repeatable read | x | x | o | o |
| dirty read | x | x | x | o |
- 팬텀 리드(phantom read)
- 한 트랜잭션 내에서 동일한 쿼리를 보냈을 때, 조회 결과가 다른 경우를 의미
- 트랜잭션 수행 중 다른 트랜잭션에 의해 기존 데이터가 변경된 경우 발생 가능
- 반복 가능하지 않은 조회(non-repeatable read)
- 한 트랜잭션 내의 같은 행에 두 번 이상의 데이터 조회가 발생했을 때, 조회 결과가 다른 경우
- 트랜잭션 수행 도중 다른 트랜잭션에서 커밋한 수정 내역에 의해 조회 결과가 바뀌는 경우 발생 가능
- 더티 리드(dirty read)
- 다른 트랜잭션에 의해 수정된 값이나, 아직 커밋되지 않은 값을 가져오는 경우
Serializable 쪽에 가까운 격리 레벨일수록, 더 많은 동시성 관련 문제들을 해결할 수 있습니다.
하지만, 그에 따라서 수율(throughput), 즉 일의 효율성이 줄어드는 trade-off가 발생합니다.
따라서 격리 수준이 높아 동시성 문제가 해결된다고 하여 마냥 좋은 것이 아님을 파악할 수 있고, 이 점에 유의해서 Transaction Isolation Level을 선택할 수 있어야 할 것으로 생각됩니다.
DeadLock (교착상태)
다시 data의 lock에 대한 개념 정리로 돌아와서 이번에는 lock을 적용하는 방식에 따라 발생할 수 있는 deadlock이라는 문제 상황을 정리해 봅시다.
Deadlock, 우리말로 교착상태는 두 개의 트랜잭션이 서로 요구하는 lock이 엇갈려서 무한정 대기하고 있는 상태에 접어드는 상태를 의미합니다.
예를 들면 이런 시나리오를 들 수 있을 것 같습니다.
- 사용자 A가 종이를 Lock
- 사용자 B가 연필을 Lock
- 사용자 A의 연필 자원에 대한 Lock 요청
- 사용자 B의 종이 자원에 대한 Lock 요청
- 사용자 A가 연필 대기 상태에 접어듦
- 사용자 B가 종이 대기 상태에 접어듦
이런 상황을 사용자 A, B가 "교착상태"에 빠졌다고 정리할 수 있습니다!!
Deadlock을 방지하기 위해 사용하는 방법
- 모든 유저(트랜잭션들)가 lock request를 동시에 하도록 한다
- 모든 애플리케이션 프로그램들이 자원들에 대한 lock을 순서에 맞게 하도록 요구한다.
Deadlock 상태에서 벗어나기 위한 방법
- 거의 모든 DBMS가 교착 상태를 감지하기 위한 알고리즘들을 구현하고 있습니다.
- 교착 상태가 발생했을 때, DBMS는 둘 중 하나의 transaction을 abort 한 뒤에 rollback 하도록 처리한다고 합니다.
'DB' 카테고리의 다른 글
| [DB] dummy data 생성과 index를 이용한 성능 개선 공부하기 (0) | 2023.03.06 |
|---|---|
| DataBase Index 개념 정리하기 (0) | 2023.02.24 |
| SELECT query가 실행되는 과정 (0) | 2023.02.21 |
| [DB] DDL, DML, DCL, TCL 이란?? (0) | 2022.08.24 |


댓글