들어가면서..
오늘은 mysql DBMS에서 dummy data를 이용해서 몇 가지 공부하고, 기록해보려고 합니다.
DataBase Index 개념 정리하기
Index에 대해서 공부해 보자😀 오늘은 index란 것에 대해서 정리해 볼까 합니다. 아무래도 DB를 구축하고 운용하는 것에 그치지 않고, 성능을 개선하기 위해 index라는 자료 구조가 꼭 필수적이기 때
kkkdh.tistory.com
지난번에 index 개념에 대한 부분만 학부 수업에서 들었던 내용 + 여러 가지 자료들을 참고해서 정리했었는데, 이번에는 sql문을 뚜드리면서 좀 더 공부하는게 목표입니다.
글을 시작할때의 목표는 일단 primary key를 제외한 다른 index를 만들어 성능 개선이 얼마나 되는지 확인하고, 또 index를 어떻게 사용하면 좋을지에 대한 개념들을 정리해보려고 하는데, 일단 공부 과정을 기록해보도록 하겠습니다.
Dummy data 부터 생성해보자!
이번 실습(?)에서 사용할 데이터는 다음 사이트에서 생성한 더미 데이터를 이용했습니다.
Mockaroo - Random Data Generator and API Mocking Tool | JSON / CSV / SQL / Excel
Mock your back-end API and start coding your UI today. It's hard to put together a meaningful UI prototype without making real requests to an API. By making real requests, you'll uncover problems with application flow, timing, and API design early, improvi
www.mockaroo.com

최대 1,000개까지 생성이 가능해서, 1,000개로 생성했습니다.
하단에 'download data'라는 버튼이 있는데, 이걸 누르면 다운 받을 수 있습니다.
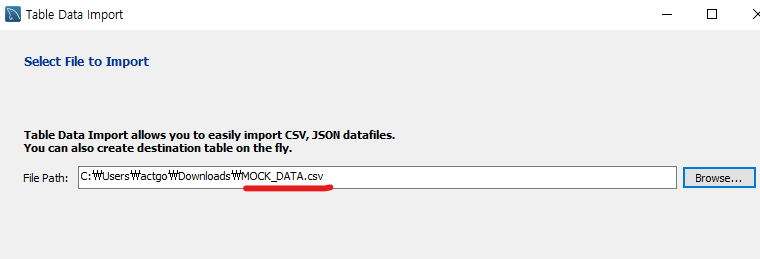
테이블을 새로 생성해서 dummy data를 넣어줍니다.
저는 test라는 테이블을 만들어서 저장했습니다.
기본 상태에서 조회 쿼리의 시간 측정
기본적으로 workbench에서 쿼리를 실행하면, 초 단위에서 소수점 세 자리까지 시간이 뜨긴 하는데, 이 단위로 보면 수치에서 유의미한 차이를 확인하기 어렵고, 데이터도 1,000개 밖에 없어서 query profiling이라는 기능을 활용해서 쿼리의 성능을 확인하기로 했습니다.
Query Profiling: profiling을 설정한 이후부터 실행하는 모든 쿼리의 수행 시간을 기록하는 기능

이름이 profiling인 이유는 쿼리에 대한 설명을 하는 개념이라 그런 것 같은데, 자세히는 모르겠습니다.
이렇게 query profiling을 활성화한 다음부터는 실행된 쿼리의 시간이 측정되는데, show profiles; 이라는 명령어를 통해 실행 시간들을 조회할 수 있습니다.

query profiling을 이용해서 좀 더 세부적인 성능 비교가 가능한 것 같은데, 이번에는 건너띄도록 하겠습니다.
다양한 쿼리의 성능 비교
먼저 어느 필드에 index를 적용하면 좋을지 알아보기 위해서, test table의 구조를 확인합니다.
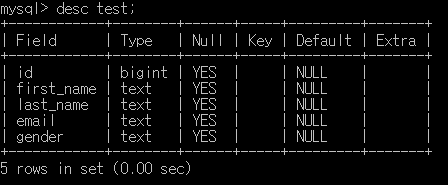
ID는 이미 PK 이므로, index가 적용되어 있기 때문에 제외하고, first_name field에 index를 적용해보면 어떨까 싶습니다.
일단 first_name에 index를 적용하지 않은 상태에서 조회 성능을 측정해 봅니다.

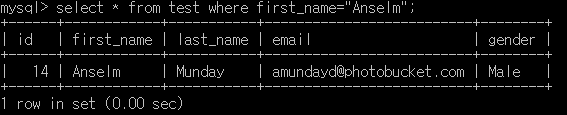
두 개의 쿼리를 실행해 봤는데, 데이터가 1개 밖에 조회가 안되어서 뭔가 불안합니다..

일단 성능은 이렇게 나오는데, 뭔가 INDEX를 적용해도 유의미한 향상이 이뤄질지 모르겠어서 다시 앞 단계로 돌아가서 dummy data를 9,000개 추가한 다음 다시 실행해 봅시다.
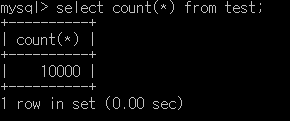
위 사이트에서 1,000개씩 9번을 더 만들어서 추가하는데 뭔가 이상해서 보니까, id 칼럼에 primary key 설정이 안되어 있어서 갈아 엎고 다시 했습니다.
설정한 다음에는 id 칼럼을 제외하고, import 해줘야 정상적으로 추가됩니다. (PK라서 중복 불가능함)

어쨌든 다시 두 개의 쿼리를 실행해 봅니다.

대략8ms, 7ms 정도 걸리는 것 같습니다. (이것도 너무 작긴한데..) 이제 first_name에 index를 만들어서 조회 성능을 개선해 봅시다.
그럴려면, index를 만들어야 하는데, index 만드는 방법을 먼저 정리해 보겠습니다.
INDEX 적용하는 방법
1. 인덱스 생성
CREATE INDEX <index name> on <table name> (column1, column2...)
2. 테이블 생성과 동시에 인덱스 생성
CREATE TABLE ...(
INDEX <index name> (column1, column2...)
or
UNIQUE INDEX ~~~ (동일) ~~~
);
3. 테이블을 수정하는 상황에서 인덱스 생성
ALTER TABLE <table name> ADD INDEX <index name> (column1, column2...)
4. 인덱스 조회
SHOW INDEX FROM <table name>;
5. 인덱스 삭제
ALTER TABLE <table name> DROP INDEX <index name>;
이제 INDEX 생성하고 비교해보자.
이미 테이블을 만들었기 때문에, 그냥 새로 index를 만들겠습니다.

그래서 만드는데, 이렇게 오류가 발생하네요
MySQL error: key specification without a key length
I have a table with a primary key that is a varchar(255). Some cases have arisen where 255 characters isn't enough. I tried changing the field to a text, but I get the following error: BLOB/TEXT c...
stackoverflow.com
이 글을 참고하니까, mysql에서 index를 만드는 경우 BLOB, TEXT type 칼럼을 index로 설정하는 경우 uniqueness를 보장할 수 없어서 길이를 N개로 제한해야 index를 만들 수 있다고 합니다.
아마 이거는 데이터를 생성할때, varchar type으로 생성된게 아니라 text type으로 column들이 생성되서 그런것 같습니다.
어쨌든 문제를 해결하려면, N 값을 제공하면 되는 문제여서 다음과 같이 index를 생성했습니다.


자 이제 index를 생성했으니 다시 똑같은 query를 실행하고, 걸린 시간을 확인해보도록 하겠습니다.

데이터가 적어서 걱정했는데, 기존 7~8ms 정도 소모되던 작업들이 0.4~0.5ms 걸리는 작업으로 성능 개선에 성공했습니다!! 😀😀😀
INDEX를 구현하는 B+ Tree 혹은 hashing table 같은 자료 구조의 특성상 데이터의 수가 많아지면 많아질 수록 성능 개선의 효율이 증가하기 때문에, INDEX 사용이 성능 개선에 왜 필수적인지를 확인할 수 있어서 나름 재밌던 실습이었다고 생각합니다.
다음 번에는 훨씬 많은 dummy dataset과 함께 다양한 방식의 성능 개선에 대해서 공부해보면 좋을 것 같습니다!
참고한 글들
https://stackoverflow.com/questions/1827063/mysql-error-key-specification-without-a-key-length
MySQL error: key specification without a key length
I have a table with a primary key that is a varchar(255). Some cases have arisen where 255 characters isn't enough. I tried changing the field to a text, but I get the following error: BLOB/TEXT c...
stackoverflow.com
https://solbel.tistory.com/739
[MySQL] 인덱스 생성, 조회 [펌]
[MySQL] 인덱스 생성, 조회 [펌] 인덱스 만들기 1. 추가하여 만들기 CREATE INDEX ON ( 칼럼명1, 칼럼명2, ... ); 2. 테이블 생성시 만들기 끝에.... INDEX ( 칼럼명1, 칼럼명2 ) UNIQUE INDEX ( 칼럼명 ) --> 항상 유일
solbel.tistory.com
https://steady-coding.tistory.com/536
'DB' 카테고리의 다른 글
| DataBase Index 개념 정리하기 (0) | 2023.02.24 |
|---|---|
| SELECT query가 실행되는 과정 (0) | 2023.02.21 |
| 트랜잭션(Transaction)의 특징(ACID)을 포함한 여러 가지 동시성 관련 개념 정리 (0) | 2023.02.11 |
| [DB] DDL, DML, DCL, TCL 이란?? (0) | 2022.08.24 |


댓글