들어가면서..

이 글은 실전 자바 소프트웨어 개발(Real-World Software Development) 책을 읽으며 공부한 점을 기록하기 위해 작성합니다.
이번 2장에서는 입출금 내역 분석기라는 소프트웨어를 개발하고, 주어진 요구사항에 맞춰 개발하는 과정에서 단일 책임 원칙(SRP, Single Responsibility Principle)의 개념을 다루고 있습니다.
다음 repository에서 실습을 진행합니다.
https://github.com/rkdehdgns1230/Real-World-Software-Development
GitHub - rkdehdgns1230/Real-World-Software-Development: "Real World Software-Development" 실습
"Real World Software-Development" 실습. Contribute to rkdehdgns1230/Real-World-Software-Development development by creating an account on GitHub.
github.com
입출금 내역 분석기 요구 사항
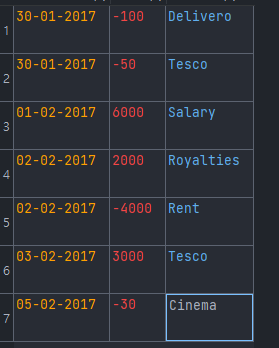
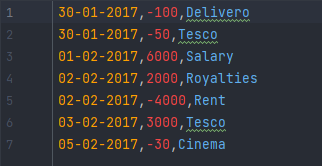
위와 같은 csv 파일 형식으로 은행 거래 내역을 입력받았을 때, 다음 문제에 대한 답을 구해야 한다.
- 은행 입출금 내역의 총수입과 총지출은 각각 얼마인가? 결과가 양수인가 음수인가?
- 특정 달엔 몇 건의 입출금 내역이 발생했는가?
- 지출이 가장 높은 상위 10건은 무엇인가?
- 돈을 가장 많이 소비하는 항목은 무엇인가?
KISS 원칙에 따른 구현
KISS 원칙은 Keep it short and simple라는 문장에서 각 단어의 앞 글자를 따 만들어진 단어로 이 원칙에 따라 책에서는 하나의 클래스로 응용 프로그램을 우선 구현한다.
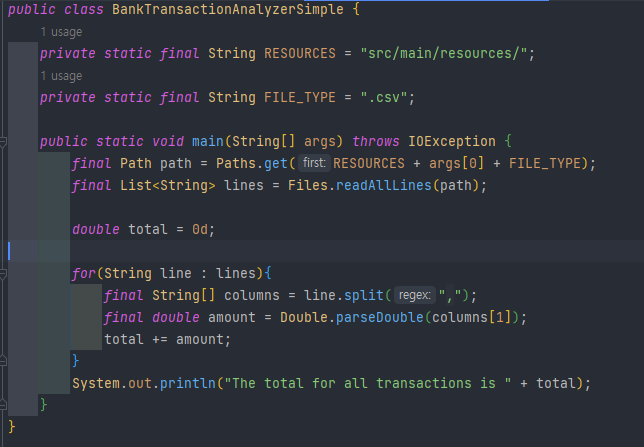
위 코드는 다음과 같은 동작을 수행
- 프로그램의 입력을 들어온 이름의 파일을 읽어옴
- 콤마로 열 분리
- 금액 추출
- 금액을 double로 parsing
파일이 빈 경우, 데이터에 문제가 있어 파싱이 실패한 경우, 행의 데이터가 완벽하지 않은 경우 같은 상황들에서 문제가 발생할 수 있으나 이는 3장에서 다룰 예정으로 일단 건너뛴다.
다음으로 두 번째 문제인 "특정 달엔 몇 건의 입출금 내역이 발생했는가?"를 다음과 같이 구현하기 위해 기존 코드를 복사해서 다음과 같이 수정한다.
final Path path = Paths.get(RESOURCES + args[0] + FILE_TYPE);
final List<String> lines = Files.readAllLines(path);
double total = 0d;
final DateTimeFormatter DATE_PATTERN = DateTimeFormatter.ofPattern("dd-MM-yyyy");
for(String line : lines){
final String[] columns = line.split(",");
final LocalDate date = LocalDate.parse(columns[0], DATE_PATTERN);
// 1월 데이터에 대한 내역의 합을 구한다.
if(date.getMonth() == Month.JANUARY){
final double amount = Double.parseDouble(columns[1]);
total += amount;
}
}
System.out.println("The total for all transactions in January is " + total);
코드 유지보수성과 안티 패턴
몇 가지 부분만 수정하여 월별 내역 합계 기능을 구현할 수 있었다.
하지만, 이렇게 복사 붙여 넣기를 통해 기능을 확장하는 것이 적절한 방법일까??
코드를 구현할 때, 기본적으로 코드 유지보수성을 고려하기 마련이고, 유지보수성을 높이기 위해서는 다음과 같은 특성들을 고려할 수 있다.
- 특정 기능을 담당하는 코드를 쉽게 찾을 수 있어야 한다.
- 코드가 어떤 일을 수행하는지 쉽게 이해할 수 있어야 한다.
- 새로운 기능을 쉽게 추가하거나 기존 기능을 쉽게 제거할 수 있어야 한다.
- 캡슐화(Capsulation)가 잘 되어 있어야 한다. 즉, 코드 사용자에게는 세부 구현 내용이 감춰져 있으므로 사용자가 쉽게 코드를 이해하고, 기능을 바꿀 수 있어야 한다.
그런 측면에서 봤을 때, "복사 붙여 넣기 방식"에 따라 다음과 같은 안티 패턴(anti-pattern) 발생한다.
- 한 개의 거대한 갓 클래스(god class)때문에, 코드 이해가 어렵다.
- 하나의 클래스로 모든 문제를 해결함에 따라 발생하는 안티 패턴
- 코드를 이해하기 어려워진다.
- 단일 책임 원칙(SRP)의 적용을 통해 해결 가능
- 코드 중복(code duplication) 때문에, 코드가 불안정하고 변화에 쉽게 망가진다.
- 각 문제에서 입력을 읽고, 파싱 하는 로직이 중복
- 중복되는 코드의 처리 방식이 바뀐다면, 모든 코드를 일일이 수정해야 한다.
- 중복되는 코드를 따로 분리하여 해결 가능
KISS (Keep it short and simple)을 지키는 것도 중요하나, 남용함에 따라 복잡성이 오히려 증가하는 상황을 경계해야 한다.
단일 책임 원칙 (SRP, Single Responsibility Principle)
객체지향 프로그래밍 설계 원칙 중 하나로
- 한 클래스는 하나의 기능만 책임진다.
- 클래스가 바뀌어야 하는 이유는 오직 하나여야 한다.
두 가지를 보완하기 위해 SRP를 적용한다.
이에 따라서 기존의 코드의 전체 책임을 다음과 같이 분리 가능하다.
- 입력 읽기
- 주어진 형식의 입력 파싱
- 결과 처리
- 결과 요약 리포트
각각 BankTransaction(domain class), BankStatementCSVParser(csv data parsing)라는 이름으로 두 개의 클래스를 생성해 입력 읽기라는 책임을 갓 클래스에서 다음과 같이 분리한다.
package com.study.chapter2;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import java.util.List;
import static java.util.stream.Collectors.toList;
public class BankStatementCSVParser {
private static final DateTimeFormatter DATE_PATTERN = DateTimeFormatter.ofPattern("dd-MM-yyyy");
private BankTransaction parseFromCSV(final String line){
final String[] columns = line.split(",");
final LocalDate date = LocalDate.parse(columns[0], DATE_PATTERN);
final double amount = Double.parseDouble(columns[1]);
final String description = columns[2];
return new BankTransaction(date, amount, description);
}
public List<BankTransaction> parseLinesFromCSV(final List<String> lines){
return lines.stream()
.map(this::parseFromCSV)
.collect(toList());
}
}위 클래스는 CSV 파일에서 읽은 데이터를 parsing 해 BankTransaction 객체로 만드는 작업을 수행한다.
package com.study.chapter2;
import java.time.LocalDate;
import java.util.Objects;
public class BankTransaction {
private final LocalDate date;
private final double amount;
private final String description;
public BankTransaction(LocalDate date, double amount, String description) {
this.date = date;
this.amount = amount;
this.description = description;
}
public LocalDate getDate() {
return date;
}
public double getAmount() {
return amount;
}
public String getDescription() {
return description;
}
@Override
public String toString(){
return "BankTransaction{" +
"date=" + date +
"amount=" + amount +
"description=" + description + "\n}";
}
@Override
public int hashCode() {
return Objects.hash(date, amount, description);
}
@Override
public boolean equals(Object obj) {
if(this == obj) return true;
if(obj == null || getClass() != obj.getClass()) return false;
BankTransaction that = (BankTransaction) obj;
// 동등성 비교
return Double.compare(this.amount, that.amount) == 0 &&
date.equals(that.date) &&
description.equals(that.description);
}
}
이제 기존 코드를 BankStatementCSVParser의 parseLinesFromCSV() method를 이용해 리팩토링 한다.
package com.study.chapter2;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.time.Month;
import java.util.ArrayList;
import java.util.List;
public class BankTransactionAnalyzerSRP {
private static final String RESOURCES = "src/main/resources/";
private static final String FILE_TYPE = ".csv";
private static final BankStatementCSVParser bankStatementParser = new BankStatementCSVParser();
public static void main(String[] args) throws IOException {
final Path path = Paths.get(RESOURCES + args[0] + FILE_TYPE);
final List<String> lines = Files.readAllLines(path);
List<BankTransaction> bankTransactions = bankStatementParser.parseLinesFromCSV(lines);
System.out.println("The total for all transactions is " + calculateTotalAmount(bankTransactions));
System.out.println("Transactions in January " + selectInMonth(bankTransactions, Month.JANUARY));
}
public static double calculateTotalAmount(final List<BankTransaction> bankTransactions){
double total = 0d;
for(BankTransaction bankTransaction : bankTransactions){
total += bankTransaction.getAmount();
}
return total;
}
public static List<BankTransaction> selectInMonth(final List<BankTransaction> bankTransactions, final Month month){
final List<BankTransaction> bankTransactionsInMonth = new ArrayList<>();
for (final BankTransaction bankTransaction : bankTransactions){
if(bankTransaction.getDate().getMonth().equals(month)){
bankTransactionsInMonth.add(bankTransaction);
}
}
return bankTransactionsInMonth;
}
}앞선 개선 사항에 추가로 calculateTotalAmount, selectInMonth method를 이용해 입출금 내역에 대한 통계 작업의 책임을 main method에 분리하는 작업을 수행했다.
리팩토링 결과
- 입력을 처리하고 파싱 하는 책임을 BankStatementCSVParser 클래스로 분리함에 따라 parsing 작업 시 수정 범위를 제한할 수 있게 되었다.
- BankTransaction 클래스 덕분에 다른 코드가 특정 데이터 형식에 의존하지 않게 되었다.
- 통계를 계산하는 작업을 별도의 메서드로 구현해 책임을 분리하였다.
응집도
응집도(cohension)는 "서로 어떻게 연관되어 있는지"를 의미하는 단어로 코드 유지보수성을 결정하는 중요한 개념이다.
더 자세하게 말하자면, 응집도는 클래스나 메서드의 책임이 서로 얼마나 강하게 연결되어 있는지를 측정하는 지표이다.
높은 응집도는 개발자의 목표로 이는 곧 서로 밀접하게 연관되어 있는 클래스나 메서드를 구현하는 것을 목표로 해야 함을 의미한다.
그러나, 앞서 BankStatementAnalyzer 클래스에 구현한 계산 관련 정적 메서드(calculateTotalAmount, selectInMonth)는 BankStatementAnalyzer가 파서, 계산, 결과 출력 등 전체 작업을 연결하는 역할을 담당한다는 측면에서 응집도를 떨어뜨리고 있는 케이스임을 파악할 수 있다.
따라서 다음과 같이 BankStatementProcessor라는 별도의 클래스를 구현해 계산 관련 책임을 분리한다.
package com.study.chapter2;
import java.time.Month;
import java.util.List;
public class BankStatementProcessor {
private final List<BankTransaction> bankTransactionList;
public BankStatementProcessor(List<BankTransaction> bankTransactionList) {
this.bankTransactionList = bankTransactionList;
}
public double calculateTotalAmount(){
double total = 0;
for(final BankTransaction bankTransaction : bankTransactionList){
total += bankTransaction.getAmount();
}
return total;
}
public double calculateTotalInMonth(final Month month){
double total = 0;
for(final BankTransaction bankTransaction : bankTransactionList){
if(bankTransaction.getDate().getMonth().equals(month)){
total += bankTransaction.getAmount();
}
}
return total;
}
public double calculateTotalForCategory(final String category){
double total = 0;
for(BankTransaction bankTransaction : bankTransactionList){
if (bankTransaction.getDescription().equals(category)) {
total += bankTransaction.getAmount();
}
}
return total;
}
}이를 통해 다시 다음과 같이 BankAnalyzer를 리팩토링 가능
package com.study.chapter2;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.time.Month;
import java.util.List;
public class BankStatementAnalyzerWithProcessor {
private static final String RESOURCES = "src/main/resources/";
private static final String FILE_TYPE = ".csv";
private static final BankStatementCSVParser bankStatementParser = new BankStatementCSVParser();
public static void main(String[] args) throws IOException {
final Path path = Paths.get(RESOURCES + args[0] + FILE_TYPE);
final List<String> lines = Files.readAllLines(path);
List<BankTransaction> bankTransactionList = bankStatementParser.parseLinesFromCSV(lines);
final BankStatementProcessor bankStatementProcessor = new BankStatementProcessor(bankTransactionList);
System.out.println("The total for all transactions is " + bankStatementProcessor.calculateTotalAmount());
System.out.println("The total for all transactions in January is " + bankStatementProcessor.calculateTotalInMonth(Month.JANUARY));
System.out.println("The total for all transactions in February is " + bankStatementProcessor.calculateTotalInMonth(Month.FEBRUARY));
System.out.println("The total salary received is " + bankStatementProcessor.calculateTotalForCategory("Salary"));
}
}
클래스 수준에서 다음과 같은 6가지 방법으로 그룹화를 진행하며, 그룹화에 따라 응집도가 높아지거나 낮아질 수 있다.
- 기능
- 유사한 기능을 갖는 메서드를 그룹화
- 하지만, 너무 한 개의 메서드를 갖는 클래스 개수를 늘린다는 경향이 발생할 수 있다는 약점 존재
- 정보
- 같은 데이터나 도메인 객체를 처리하는 메서드를 그룹화
- DAO (Data Access Object)를 만들어 하나의 도메인 객체에 대한 작업을 그룹화하는 상황을 예시로 들 수 있다.
- 다만, 여러 기능을 그룹화함에 따라 필요한 일부 기능을 위해 전체 클래스에 대한 의존성이 생긴다는 약점이 존재
- 유틸리티
- 때로는 관련성이 적은 메서드를 하나의 클래스로 묶는 경우 존재
- 이럴 때, 유틸리티 클래스에 메서드를 모으게 되는데, 이는 응집도를 낮춘다.
- 논리
- 동일한 논리로 그룹화가 가능하지만, 이는 본질적으로 관련이 없는 메서드들일 수 있다.
- 이러한 경우 SRP를 위배하여 여러 책임을 하나의 클래스가 맡게 되어, 응집도를 낮출 수 있다.
- 순차
- 입출력이 순차적으로 흐르는 것을 순차 응집이라고 부른다.
- 이에 따라 한 클래스가 마찬가지로 여러 책임을 맡게 되고, 수정할 부분이 많아져 SRP를 위배
- 시간
- 시간 응집 클래스는 시간과 관련된 연산을 그룹화한다.
- 어떤 처리 작업 이전에 수행해야 하는 초기화나 뒷정리 작업이 이에 해당한다.
표로 정리하면, 다음과 같다.
| 응집도 수준 | 장점 | 단점 |
| 기능(높은 응집도) | 이해하기 쉬움 | 너무 단순한 클래스 생성 |
| 정보(중간 응집도) | 유지보수하기 쉬움 | 불필요한 dependency 생성 |
| 순차(중간 응집도) | 관련 동작을 찾기 쉬움 | SRP를 위배할 수 있음 |
| 논리(중간 응집도) | 높은 수준의 카테고리화 제공 | SRP를 위배할 수 있음 |
| 유틸리티(낮은 응집도) | 간단히 추가 가능 | 클래스의 책임을 파악하기 어려움 |
| 시간(낮은 응집도) | 판단 불가 | 각 동작을 이해하고 사용하기 어려움 |
결합도
응집도 외에 코드를 구현할 때, 고려해야 하는 추가적은 특성으로는 결합도(coupling)가 있다.
응집도가 클래스, 패키지, 메서드 등의 동작이 서로 얼마나 연관되어 있는지를 의미하는 지표라면, 결합도는 어떤 클래스를 구현하는데 얼마나 많은 클래스에 의존하고 있는지(알고 있는지 or 참조하고 있는지)를 가늠하는 지표라고 정리할 수 있다.
예제에서 BankStatementAnalyzer는 BankStatementCSVParser 클래스에 의존하고 있었다.
그런데, 이 상황에서 만약 csv 파일이 아닌 xml 파일로부터 parsing 해야 한다는 요구 사항의 변경이 발생한다면??
→ 아주 성가신 리팩토링을 해야 할 것!!
이런 상황에서 interface를 도입해 interface에 의존하게 함으로써 결합도를 낮출 수 있다.
이는 구현체(implementation)가 아닌 추상체(interface)에 의존하도록 코드를 변경함으로써 의존하는 대상을 변경함으로써 결합도를 낮춘다는 것으로 이해할 수 있을 것 같다. (이는 곧 DIP(Dependency Inversion Principle, 의존 역전 원칙)를 지킴을 의미한다)
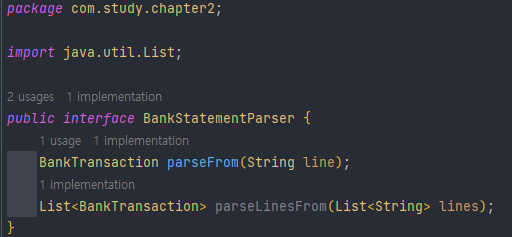
따라서 다음과 같이 interface로 BackStatementParser를 만들고, interface를 BackStatementCSVParser가 구현하도록 변경하면, 더 확장성 있고, 특정 구현에 의존하지 않는 방식으로 클래스 개선이 가능하다.

원래 클래스에서는 다음과 같이 추상화에 알맞은 구현체의 의존성을 주입해서 사용하도록 변경
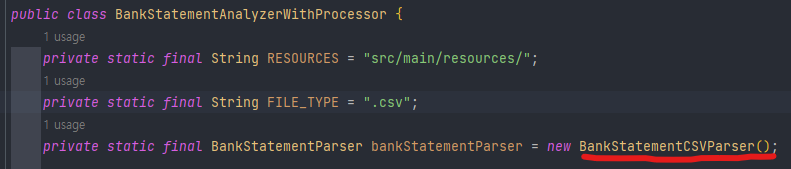
Spring container를 사용한다면, 이런 의존성 주입을 알아서 해주겠지만, 지금은 순수 Java를 이용하기 때문에, 직접 의존성을 주입해줘야 한다.
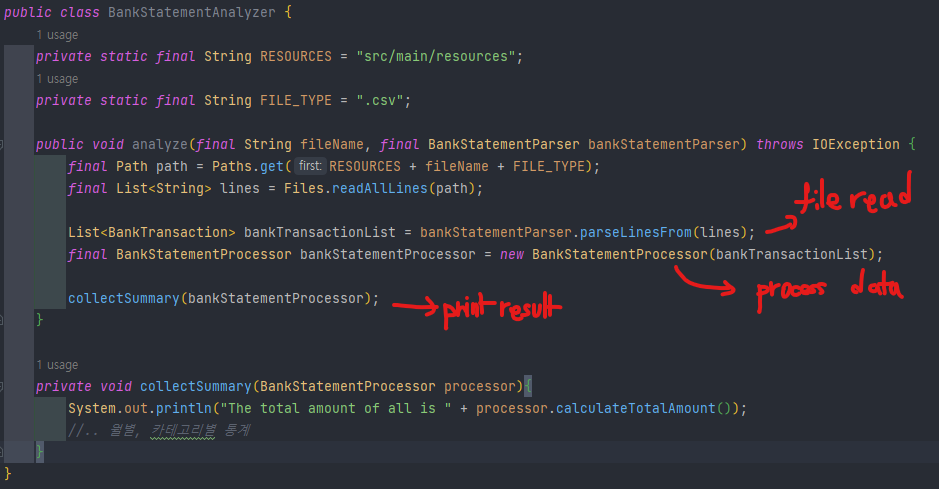
다시 돌아와서 책에서는 일부 과정이 생략된 것 같은데, BankStatementAnalyzer를 다음과 같이 개선해 준다. (결과 출력하는 로직도 분리하고, Analyzer의 역할을 여러 책임을 연결하는 것으로 변경)
(사실 결과 출력도 별도의 클래스로 분리하는 것이 적합해 보이기는 합니다.)
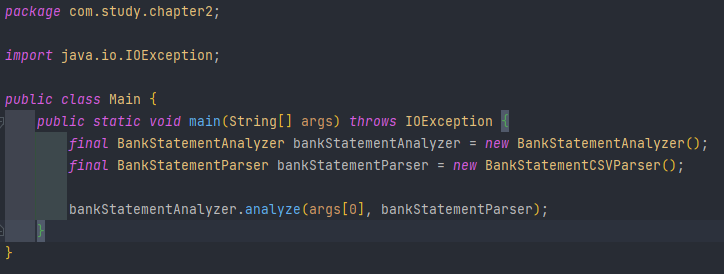
이제 이를 Main class에서 호출하도록 변경하여 마무리
결론은 코드를 짤 때, 응집도를 높이되 결합도를 낮춰야 한다는 것이다.
테스트
마지막으로 JUnit을 이용해 테스트 코드를 작성한다.
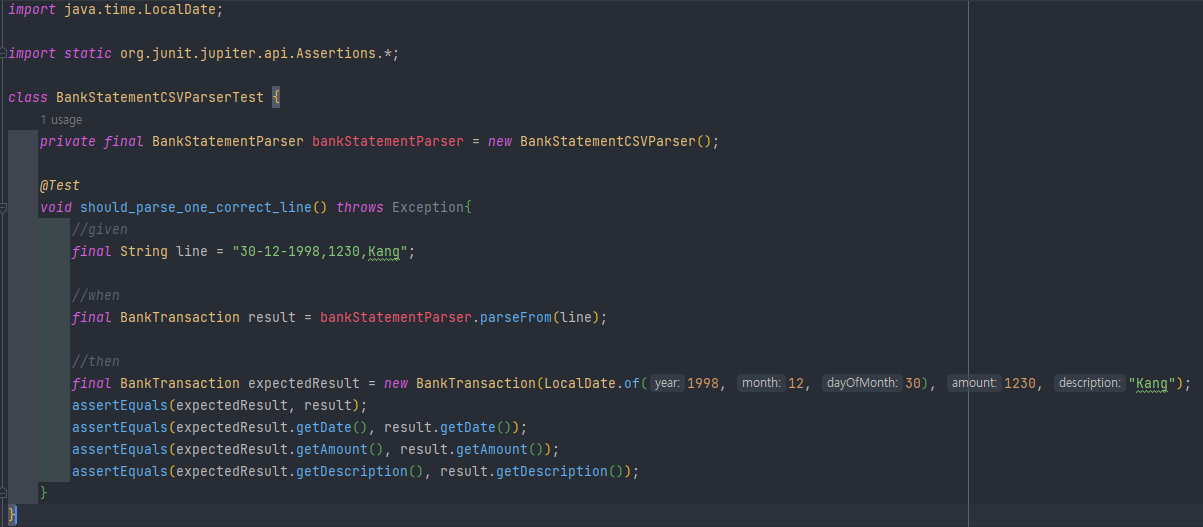
테스트 코드 작성을 통해 얻을 수 있는 이점
- 확신
- 소프트웨어가 규격 사항에 알맞은지 테스트를 통해 확인 가능
- 변화에도 튼튼함 유지
- 코드를 변경했을 때, 테스트 코드 실행을 통해 올바르게 변경되었는지 확인 가능
- 자동화된 테스트 스위트(suite)를 통해 새로운 버그 확인이 쉽고 간편
- 프로그램 이해도
- 테스트 코드를 통해 소프트웨어의 전체 개요를 빠르게 파악 가능
'Book' 카테고리의 다른 글
| [실전 자바 소프트웨어 개발] 5. 비즈니스 규칙 엔진 (0) | 2023.09.04 |
|---|---|
| [실전 자바 소프트웨어 개발] 4. 문서 관리 시스템 (0) | 2023.08.31 |
| [실전 자바 소프트웨어 개발] 3. 입출금 내역 분석기 확장판 (0) | 2023.08.29 |
| [리뷰] "스프링부트와 AWS로 혼자 구현하는 웹 서비스"를 읽고나서 (0) | 2023.08.27 |




댓글