객체 지향 쿼리 언어 JPQL 이란
JPA에서는 다양한 쿼리 방식을 지원한다.
- JPQL
- JPA Criteria
- QueryDSL
- 네이티브 SQL
- JDBC API 직접 사용, MyBatis, SpringJdbcTemplate을 JPA와 같이 사용
앞서 배웠던 엔티티 조회 방식은 Entity manager의 find method 호출을 통한 조회 혹은 객체 그래프 탐색(ex entityA.getB())을 통한 entity 조회였다.
하지만, 조건을 포함한 검색 쿼리 같은 경우는 앞서 사용한 방식으로는 해결이 불가능하다. JPA를 사용하는 경우 엔티티 객체를 중심으로 개발을 할 수 있게 되지만, 결국 애플리케이션에서 필요한 데이터만 조회하기 위해서는 SQL의 도움이 필요하다.
JPQL
이러한 문제를 해결하기 위해 JPQL이 제공된다.
- JPA는 SQL을 추상화한 JPQL이라는 객체 지향 쿼리 언어를 제공한다.
- SQL과 문법이 매우 유사하며, SELECT, FROM, WHERE, GROUP BY, HAVING, JOIN을 지원한다.
- JPQL은 SQL과 달리 엔티티 객체를 대상으로 쿼리
- SQL은 DB 테이블을 대상으로 쿼리
List<Member> resultList = em.createQuery("select m from Member m where m.name like '%kang%'"
, Member.class)
.getResultList();간단한 JPQL 예시는 위와 같다. JPQL의 경우 SQL을 추상화해서 만들어졌기 때문에, 특정 DBMS에 의존하지 않는다.
JPQL을 한마디로 정의하면 객체 지향 SQL이라고 할 수 있다고 한다.
Criteria
하지만, JPQL만 사용하는 경우 동적 쿼리를 만드는데 있어서 굉장히 까다롭다는 단점이 발생한다. 이를 해결하기 위해 JPA 표준으로 Criteria라는 것을 제공한다.
- Criteria 사용시 문자가 아닌 자바 코드로 JPQL을 작성할 수 있으며
- JPQL 빌더 역할을 한다.
- JPA 공식 기능이지만,
- 너무 복잡하고 실용성이 없다는 단점이 있다.
- 따라서 김영한님은 Criteria 대신 QueryDSL 사용을 권장한다고 하심
QueryDSL
- QueryDSL을 사용하면 마찬가지로 문자가 아닌 자바 코드로 JPQL을 작성할 수 있다.
- JPQL 빌더 역할을 한다.
- 컴파일 시점에서 문법 오류를 찾을 수 있다.
- 동적 쿼리 작성이 편리하다.
- 여기까지는 Criteria와 같은 장점을 갖지만, Criteria 보다 훨씬 단순하고 쉽다는 장점을 갖는다고 한다.
- 따라서 실무 사용을 권장한다고..
Native SQL
다음과 같이 JPA에서 native SQL을 사용하는 기능도 지원해준다.
String sql = "select id, age, team_id, name from MEMBER where name = 'kim'";
em.createNativeQuery(sql, Member.class).getResultList();하지만, native sql을 직접 사용하는 것 보다 JDBC나 SpringJdbcTemplate 등을 사용하는 것이 훨씬 편리
JDBC 직접 사용, SpringJdbcTemplate 등..
- JPA를 사용하며 JDBC 커넥션을 직접 사용하거나, SpringJdbcTemplate, MyBatis 등을 같이 사용할 수 있다.
- 하지만, 이 때에는 영속성 컨텍스트를 적절한 시점에 flush 하는 것이 매우 중요하다.
- 예시) JPA를 우회해서 SQL을 실행하기 직전에 영속성 컨텍스트를 수동 플러시 한다.
JPA에서 영속성 컨텍스트가 flush 되는 시점은 commit 되거나 query를 실행하는 두 가지 경우임을 명심하자!!
기본 문법과 쿼리 API
JPQL은 SQL을 추상화해서 특정 데이터베이스의 SQL에 의존하지 않는다는 점은 굉장히 중요한 포인트이다.
JPQL의 문법은 다음과 같이, SQL과 매우 유사하다.

- 예시) select m from Member as m where m.age > 18
- 엔티티와 속성은 대소문자 구분 O (Member, age)
- JPQL 키워드는 대소문자 구분 X (select or SELECT 상관없다)
- 엔티티 이름을 사용하며, 테이블 이름이 아니다. (Member)
- 별칭은 필수 (m, as keyword 생략이 가능)
- JPA 표준 스펙에 따르면, 별칭이 필수. hibernate는 없이도 가능하지만, 웬만하면 표준을 따르자.
집합과 정렬
다음과 같이 grouping과 정렬 기능을 모두 SQL과 동일하게 제공한다.
TypedQuery vs Query
- TypeQuery: 반환 타입이 명확할때
- Query: 반환 타입이 명확하지 않을때
두 가지는 crateQuery method 반환 결과를 다룰때 사용하는 타입으로, 쿼리의 반환 타입이 명확한 경우 TypeQuery<type> 형태로 사용하고, 명확하지 않은 경우 Query로 반환 타입을 명시한다.
결과 조회 API
- getResultList method: 결과가 하나 이상인 경우 리스트 반환
- 결과가 없는 경우 빈 리스트 컬랙션을 반환
- getSingleResult method: 결과가 하나인 경우 단일 객체 반환
- 결과 없는 경우 javax.persistence.NoResultException
- 둘 이상인 경우 javax.persistence.NonUniqueResultException
따라서 getSingleResult method를 사용해서 결과를 반환받는 경우, 에러를 handling 하도록 로직을 구현하거나 Optional을 활용해야할 것이다.
Spring Data JPA를 사용하면, null을 반환하거나 Opitional을 사용해서 알아서 처리해준다고 한다.
사실 이미 프로젝트에서 오류를 반환하는 문제 때문에, Optional 객체 개념을 공부해서 적용해 처리한 경험이 있다.
파라미터 바인딩
이름을 기준으로 바인딩

setParameter method를 chaining 해서 구현한 예시이다.
em.createQuery("select m from Member m where m.id = ?", Member.class)
.setParameter(1, 1)
.getSingleResult();위치를 기준으로도 할 수 있지만, 웬만하면 사용을 자제하도록 하자. (위치가 바뀌면 버그가 발생하기 때문이다. 매번 바꿔줘야 한다.)
프로젝션 (SELECT)
SELECT 절(clause)에 조회할 대상을 지정하는 것을 의미한다.
- 프로젝션 대상: 엔티티, 임베디드 값 타입, 스칼라 타입 (숫자, 문자열 등의 기본 데이터 타입)
- select m from Member m → 엔티티 프로젝션
- select m.team from Member m → 엔티티 프로젝션
- select t from Member m inner join m.team
- 위와 같은 코드로 개선하는 것이 코드 동작 구조 파악상 더 좋다.
- select m.address from Member m → 임베디드 값 타입 프로젝션
- select m.username, m.age from Member m → 스칼라 타입 프로젝션
- distinct를 이용한 중복 제거 가능
- select distinct m.username from Member m 과 같이 사용

여러 개의 값을 조회하는 방식
- Query 타입으로 조회
- Object[] 타입으로 조회
- new 명령어를 이용한 조회
- 단순 값을 DTO를 만들어 바로 조회하도록
- select new jpql.UserDTO(m.username, m.age) from Member m
- 패키지 경로까지 선언해야 하는 단점이 있다.
- 순서와 타입이 일치하는 DTO 생성자가 필요하다.

이렇게 여러 개의 값을 조회하는 경우 Object List의 List를 반환해주는데, Object를 또 type casting을 통해 list로 바꿔줘야 하는 복잡함이 존재한다.
위 방법들은 이걸 풀이해서 사용하는 방식들에 대한 설명이라고 생각한다. Generic을 이용해 처음부터 type casting을 받을수도 있다.
신기한 방식은 세 번째 DTO를 사용해서 바로 값을 바인딩해주는 방식이다.


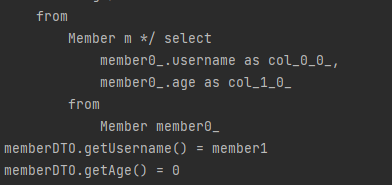
이렇게 DTO를 활용하면, 패키지 경로까지 작성해줘야 하는 불편함이 있더라도 값을 자동으로 바인딩해주는 장점이 있다.
페이징 API
JDBC를 활용해서 sql을 직접 설계해 페이징 api를 설계하는 경우 문법상 굉장히 불편한 문제들이 있었다. 사용해본 적은 없으나 오라클의 경우에는 페이징 구현을 위해 3중 select statement가 포함되어야..
- JPA는 페이징을 다음 두가지 API로 추상화한다.
- setFirstResult(int startPosition): 조회 시작할 위치
- setMaxResult(int maxResult): 조회할 데이터의 수
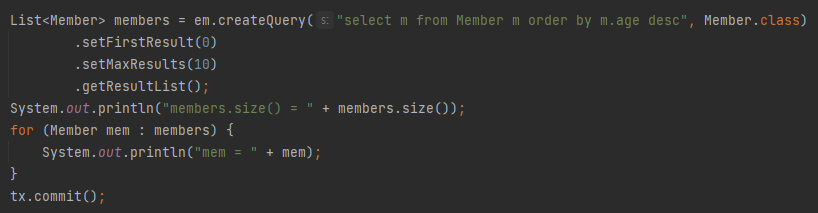
위와 같이 method를 활용하면, 0번째 위치부터 10개의 데이터를 가져오는 페이징 기능을 쉽게 구현할 수 있다.


JPQL은 DBMS의 SQL의 추상화 이므로 DBMS에 가리지 않고, 추상화된 API만을 이용해 페이징 기법을 간단하게 처리할 수 있다는 점이 굉장히 큰 장점이라고 생각된다.
조인 (JOIN)
조인의 종류를 크게 분류하면, 다음과 같다.
- 내부 조인
select m from Member m [inner] join m.team t - 외부 조인
select m from Member m left [outer] join m.team t - 세타 조인
select count(m) from Member m, Team t where m.username = t.name
여기서 내부 조인, 외부 조인에 따른 inner, outer keyword는 생략이 가능하다. 위의 예시에서 외부 조인을 left outer join만 명시했는데, right, full outer join 또한 존재한다.
세타 조인은 그냥 연관관계 없는 조인(막조인?)을 의미한다. cartesian product 진행한 뒤, join condition에 맞춰 걸러내는 형태(?)인 것 같다.

조인에 대한 개념의 자세한 설명은 여기서 생략
JOIN의 ON 절
ON 절을 활용한 join을 JPA 2.1 이후부터 지원하고 있다. ON 절은
- 조인 대상의 필터링과
- 연관관계가 없는 엔티티 끼리의 외부 조인(hibernate 5.1 이후부터)
지원하고 있다.
조인 대상의 필터링
조인 대상을 필터링한다는 것은 다음과 같은 예시를 들 수 있다고 한다.
- 회원과 팀을 조인하며, 팀 이름이 A인 팀과만 조인하자.
- JPQL:
select m, t from Member m left join m.team t on t.name = 'A' - SQL:
select m.*, t.* from Member m left join Team t on m.TEAM_ID = t.ID and t.NAME = 'A';
- JPQL:
그러니깐 join이 기본적으로 cartesian product를 진행한 이후 join condition으로 거른 데이터를 조회하는 방식으로 동작한다면, cartesian product의 대상이 될 데이터를 JPQL에서의 on 절을 사용해 지정할 수 있음을 의미한다고 이해했다.
(제가 이해한 방식이므로 올바른 개념이 아닐 수 있습니다. 틀린 개념이라면, 알려주시면 감사드리겠습니다!)
SQL이 동작하는 방식에서도, ON 절과 WHERE 절의 명확한 차이를 이해하지 않고 넘어갔던 것 같은데, ON절은 join의 대상을 필터링하고, WHERE 절은 JOIN 결과를 필터링 한다는 것을 select query 동작 순서 개념과 접목하니 수월하게 이해할 수 있었다.
SELECT query가 실행되는 과정
들어가면서.. 오늘은 database에서 데이터를 조회하기 위한 기본적인 방법인 SELECT query에서 데이터를 조회하는 과정을 단계별로 살펴보려고 합니다. SELECT query에 포함되는 where, group by, having, order by
kkkdh.tistory.com
원리를 간단히 생각하면, FROM 절이 SELECT query 상에서 가장 먼저 실행되는 절인데, 이 안에서 JOIN clause가 진행되니 이 안에서 수행되는 ON clause는 조인의 대상을 처리하는 작업을 수행하게 된다.
그리고 이후에 수행되는 WHERE 절은 당연히 조인 결과물을 필터링하는 작업을 수행할 수 밖에 없다. (위에 글을 하루 앞서서 정리했는데, 많은 도움이 된 것 같다.)
연관관계가 없는 엔티티의 외부 조인
on절을 활용해 연관관계가 없는 엔티티 끼리의 외부 조인에 대한 join 조건을 명시할 수 있습니다.

연관관계 없는 외부 조인을 진행할때, JPA에 on clause를 이용해 조건절을 명시해 조인 대상을 지정해줄 수 있게 된다.
서브 쿼리
쿼리 내에서 추가적으로 사용하는 쿼리를 의미한다. SQL에서 말하는 것과 동일한 개념
예를 들어
- 나이가 평균보다 많은 회원
- select m from Member m where m.age > (select avg(m2.age) from Member m2)
- 한 건이라도 주문한 고객
- select m from Member m where (select count(o) from Order o where m = o.member) > 0
일반적으로 SQL에서 서브쿼리를 사용할때와 마찬가지로, 서브 쿼리에 본 쿼리에서 사용하는 테이블을 끌고오는 경우 성능이 잘 나오지 않는다고 한다. (왜 그렇지?)
→
간단하게 알아본 결과 메인 쿼리의 데이터를 서브 쿼리에서 사용하는 것을 연관 서브 쿼리 그렇지 않은 경우 비연관 서브 쿼리라고 한다.
이때, 비연관 서브 쿼리는 서브 쿼리의 결과를 메인 쿼리에 제공하는 목적으로 사용되는 반면,
연관 서브 쿼리는 메인 쿼리의 데이터를 서브 쿼리가 가져와 처리한 후, 다시 메인 쿼리에 데이터를 제공하는 절차로 인한 성능 차이인 것 같다.
그룹 함수들 같은 경우에는 특히 having 절에서만 사용 가능해, 통계를 이용한 연산을 진행하는 경우 서브 쿼리를 주로 활용하는 것 같다.
서브 쿼리 지원 함수
서브 쿼리의 결과 데이터와의 연산과 관련된 로직에 대한 함수들이다.
- [NOT] EXISTS (subquery) : 서브 쿼리에 결과가 존재하면 참이다. (NOT은 반대)
- {ALL | ANY | SOME} (subquery)
- ALL은 모두 만족하면 참
- ANY, SOME: 둘은 같은 의미, 조건을 하나라도 만족하면 참
- [NOT] IN (subquery): 서브 쿼리의 결과 중 하나라도 같은 것이 있으면 참
서브 쿼리 지원 함수를 활용한 예제들

JPA 서브 쿼리의 한계
- JPA는 WHERE, HAVING 절에서만 서브 쿼리를 사용할 수 있다.
- SELECT 절은 hibernate에서 지원해준다. (표준은 안됨)
- FROM 절의 서브 쿼리는 현재 JPQL에서 불가능하다고 한다.
- 조인으로 풀어서 해결해야 한다.
보통 from 절 서브쿼리를 넣는 방식들을 sql 자체에 비즈니스 로직 등을 포함하는 경우가 많다고 한다.
따라서 김영한 님은 이러한 로직을 애플리케이션 단계에서 처리하도록 분리하는 개발 방식을 선호하신다고 한다.
JPQL에서 타입 표현
- 문자: 'HELLO', 'kang', 'She''s' 등 single quotation 사용해서 표현 (두개 써서 single quotation 하나로 표현 가능)
- 숫자: 10L(Long), 10D(Double), 10F(Float)
- Boolean: TRUE, FALSE
- ENUM: 패키지 명까지 포함해서 사용해야 한다.
- 엔티티 타입: TYPE(i) = Book (상속 관계에서 사용), 원하는 자식 엔티티 타입만 가져오고 싶은 경우에 사용 (가능한 기능이지만, 거의 사용하지 않는다고 한다.)
setParameter api를 활용한 파라미터 바인딩으로 Enum type 값 매핑 (invalid path error가 발생해서 일단 이렇게 처리했다.)
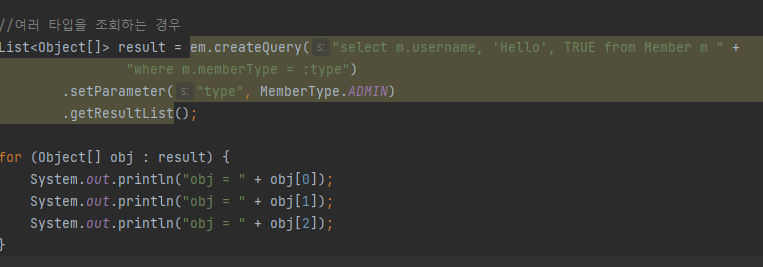
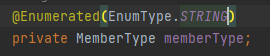
Enum type은 기본 전략이 순서에 따른 인덱스로 매핑되는 ORDINAL 전략임을 유의해서 바꿔줬다.

예외로 SQL 표준에서 제공하는 기능들을 모두 제공한다.
- EXISTS, IN
- AND, OR, NOT
- =, >, <, >=, <=, <> 모두 지원
- BETWEEN, LIKE, IS NULL, IS NOT NULL 등
조건식 - CASE 식
조건에 따라 다른 값을 조회하도록 할때, 사용할 수 있는 기능이다.
기본 CASE 식

단순 CASE 식

차이점은 크게 없고, 단순 CASE 식은 exact matching을 기반으로 동작한다는 것에만 유의하자.
추가적으로 다음과 같은 조건에 따라 다른 값을 반환하는 함수들도 있다.
- COALESCE: 하나씩 조회해서 null이 아니면 반환한다. → 모두 null이면 가장 마지막 값을 반환할 것
- NULLIF: 두 값이 같으면 null 반환, 그렇지 않으면 첫번째 값을 반환 → 관리자의 이름을 보호하고 싶을때 사용 가능

JPQL 기본 함수
JPA 표준에 따라서 다음과 같은 함수들을 제공한다.
- CONCAT
- SUBSTRING
- TRIM: 문자열에서 공백을 지우거나 하는 용도
- LOWER, UPPER
- LENGTH
- LOCATE: 특정 문자열에서 특정 패턴의 위치를 찾아준다.
- ABS, SQRT, MOD 등의 계산 함수
- SIZE, INDEX(JPA 용도): size는 엔티티 리스트의 크기를 고려할때, index는 값 타입 컬랙션에서 특정 값의 위치를 찾을때 사용
이 외에도 많은 함수들을 사용하는 경우가 실무에서 잦다고 하는데, 이는 미리 등록된 함수들이 DBMS 종속적이긴 하나 많이 존재하기 때문에, 이것을 사용하면 된다고 한다.
사용자 정의 함수
- 하이버네이트는 사용전 dialect를 추가한 뒤
- 사용자 정의 함수를 세팅에서 등록해준다.
- 그 다음 select function('group_concat', i.name) from Item i 와 같은 문법으로 사용 가능
- hibernate는 그냥 여타 함수를 사용하듯이 문법적으로 사용하는 것을 지원해준다.
'BackEnd > java spring' 카테고리의 다른 글
| Servlet에 대한 개념 정리 (1) | 2023.03.01 |
|---|---|
| [JPA] JPQL 2 - 중급 문법 정리 (0) | 2023.02.24 |
| [JPA] 값 타입 (1) | 2023.02.18 |
| [JPA] 프록시 (0) | 2023.02.15 |
| [JPA] 고급 매핑 (0) | 2023.02.06 |




댓글